Contrastive Self-Supervised Learning for Multi-modal Earth Observation Data
Fundamental Research Earth Observation Deep Learning Self-supervised Learnig Data Fusion Transformers Classification Segmentation
This research consists of two parts that will be presented in the following.
Contrastive Self-supervised Data Fusion for Satellite Imagery
Supervised learning of any task requires large amounts of labeled data. Especially in the case of satellite imagery, unlabeled data is ubiquitous, while the labeling process is often cumbersome and expensive. Therefore, it is highly worthwhile to leverage methods to minimize the amount of labeled data that is required to obtain a good performance of the given down-stream task. In our first work, we leverage contrastive learning in a multi-modal setup to achieve this result.
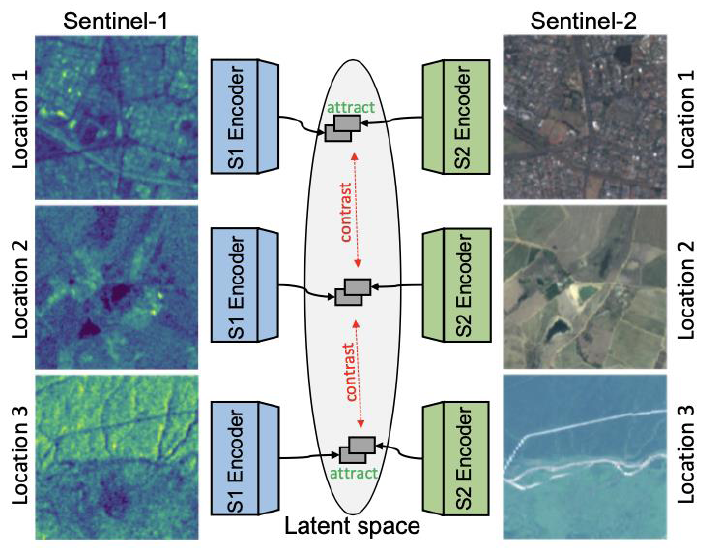
We experiment with different self-supervised learning approached including SimCLR (Chen et al., 2020) and Multi-Modal Alignment (MMA, Windsor et al., 2021) to pretrain our model. Based on SimCLR, we build our own Dual-SimCLR approach, which is depicted above. In all our approaches, we abstain from utilizing data augmentations, which typically is required for contrastive self-supervised learning. Instead, we take advantage of the co-located nature of the data modalities to construct the contrastive power required for the learning process.
We develop the Dual-SimCLR architecture for this work. Instead of using data augmentations and a shared backbone as is utilized in SimCLR, our architecture uses a separate backbone for each modality, resulting in separate representations. In the pre-training of the model, we utilize an MLP as projection head to generate latent presentations, based on which the constrastive loss operates. For the training of a down-stream task, we fine-tune the backbone and implement a fully-connected layer as classification head. The model is pre-trained on large amounts of unlabeled data and fine-tuned on small amounts of labeled data.
For pretraining, we utilize the SEN12MS (Schmitt et al., 2019) dataset, which contains co-located pairs of Sentinel-1 and Sentinel-2 patches, disregarding available labels; for fine-tuning, we utilize the GRSS Data Fusion 2020 dataset, which comes with high-fidelity LULC segmentation labels. The downstream task is learning in a single-label and multi-label approach.
Our results show that especially Dual-SimCLR is very successful in learning rich representations. The results for both single-label und multi-label downstream tasks clearly outperform a range of fully-supervised baselines that utilize single modalities or different data fusion approaches, as well as the other contrastive self-supervised approaches that were tested. We can show that the learned representations are rich and informative.
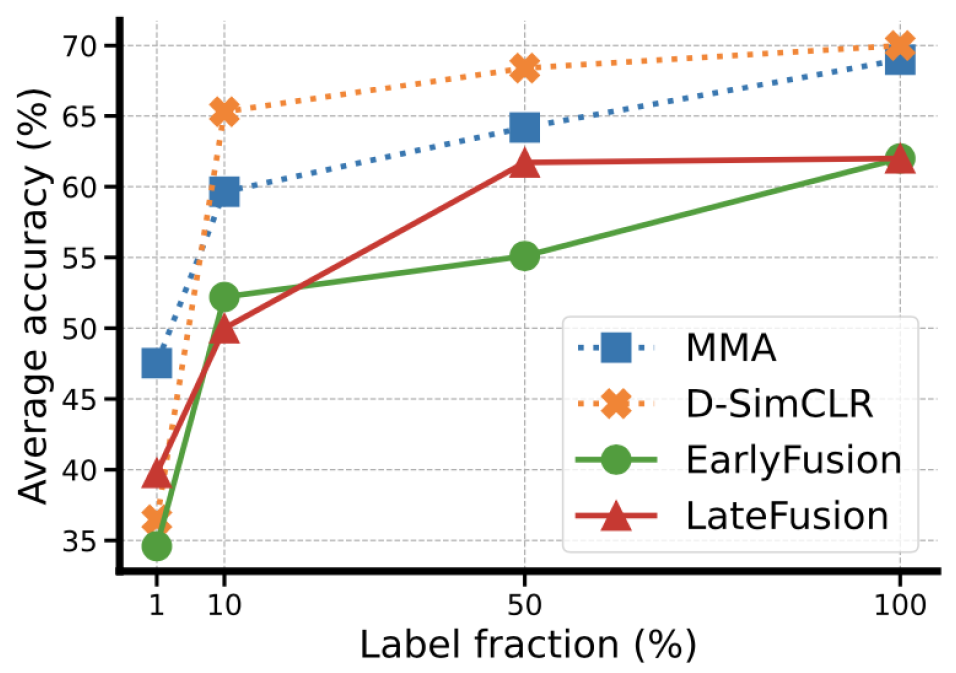
More importantly, we are able to show the efficiency of pre-training with our approach: by fine-tuning the learned representations of the pretrained backbone, we are able to outperform any fully-supervised baseline approach with only 10% of the labeled data.
To conclude, our approach enables the label-efficient training of deep learning models for remote sensing by pretraining on a large amount of unlabeled data.
The results of this study have been presented at the ISPRS 2022 congress in Nice, France (the results have been presented by Michael Mommert, but the work has been done by Linus Scheibenreif).
Self-supervised Vision Transformers for Land-cover Segmentation and Classification
In a natural extension of the previous work, we replace our previous model backbone with a pair of powerful Swin-Transformers. These backbones are pretrained in a contrastive self-supervised fashion, similar as in our previous work.
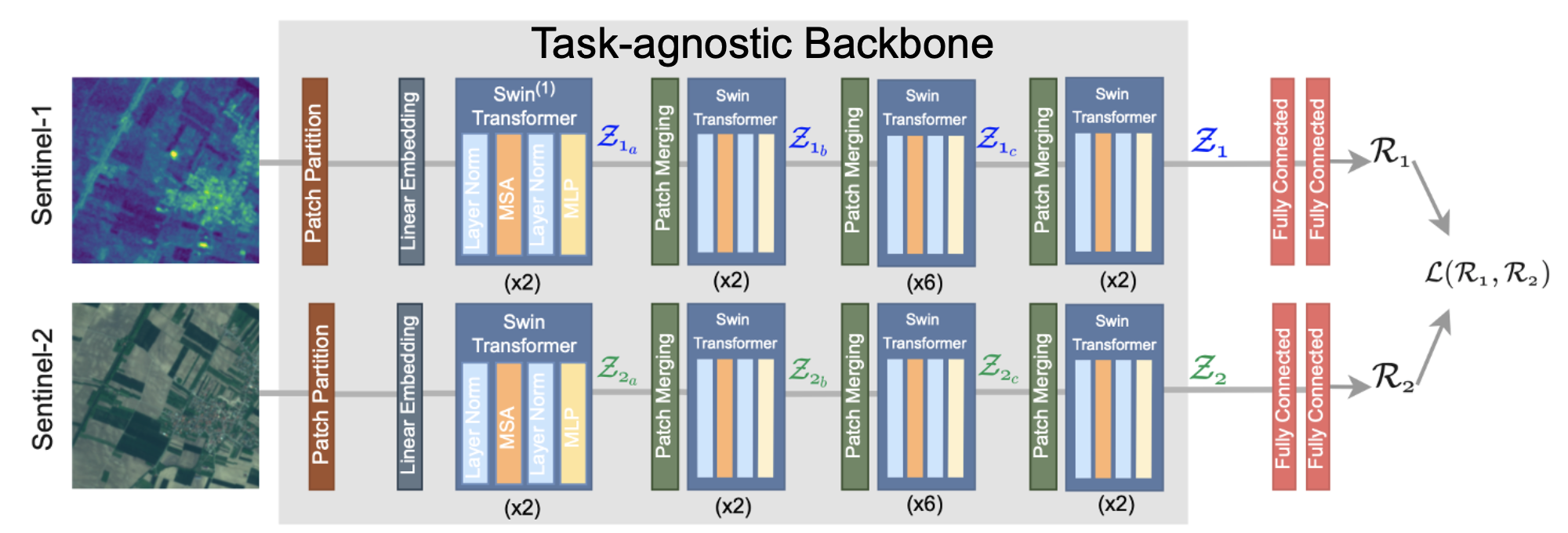
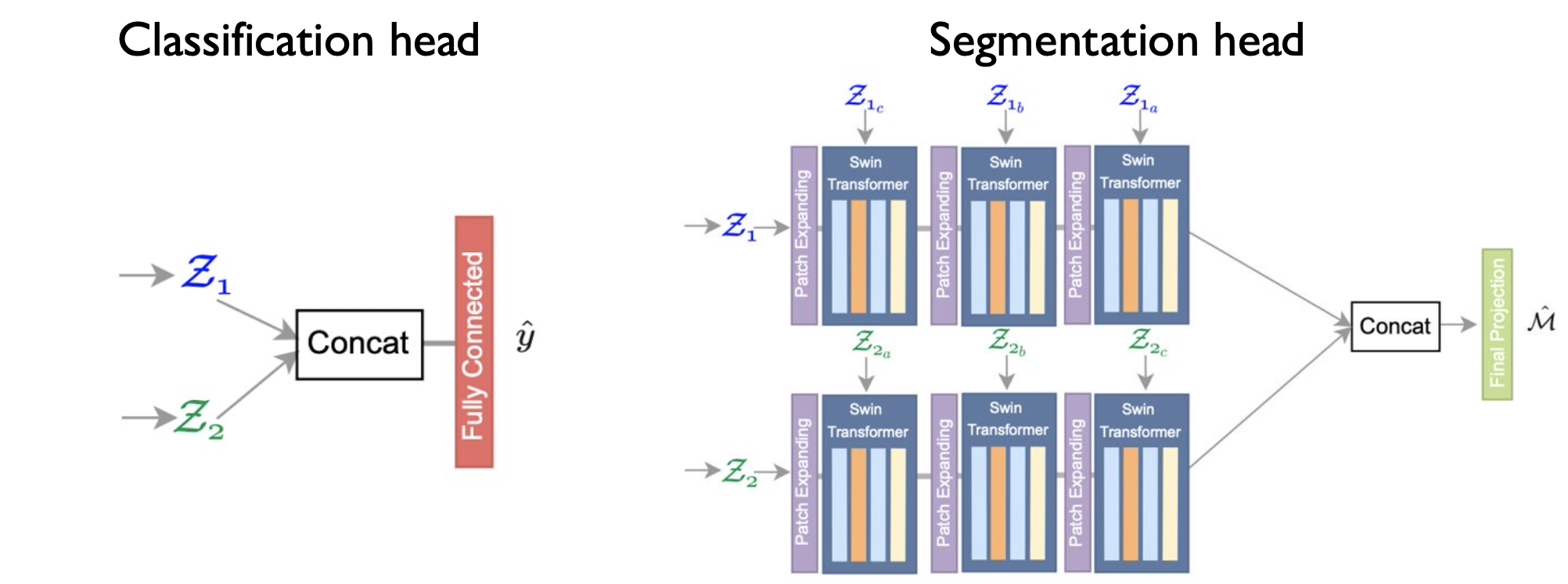
The goal of this SwinUNet architecture is to learn rich, task-agnostic representations for Earth observations applications. We test this characteristic by evaluating the pretrained model on two different tasks: patch-based image classification and semantic image segmentation, utilizing different heads for these tasks.
Our results support our assumption that the learned representations are rich and indeed task agnostic. Similarly to our previous results, we can show that for both image classification and semantic segmentation, fine-tuning on significantly smaller amounts of labeled data is able to outperform fully supervised training from scratch. Furthermore, we are able to show that Transformer architectures are successful at learning both downstream tasks with good performance.
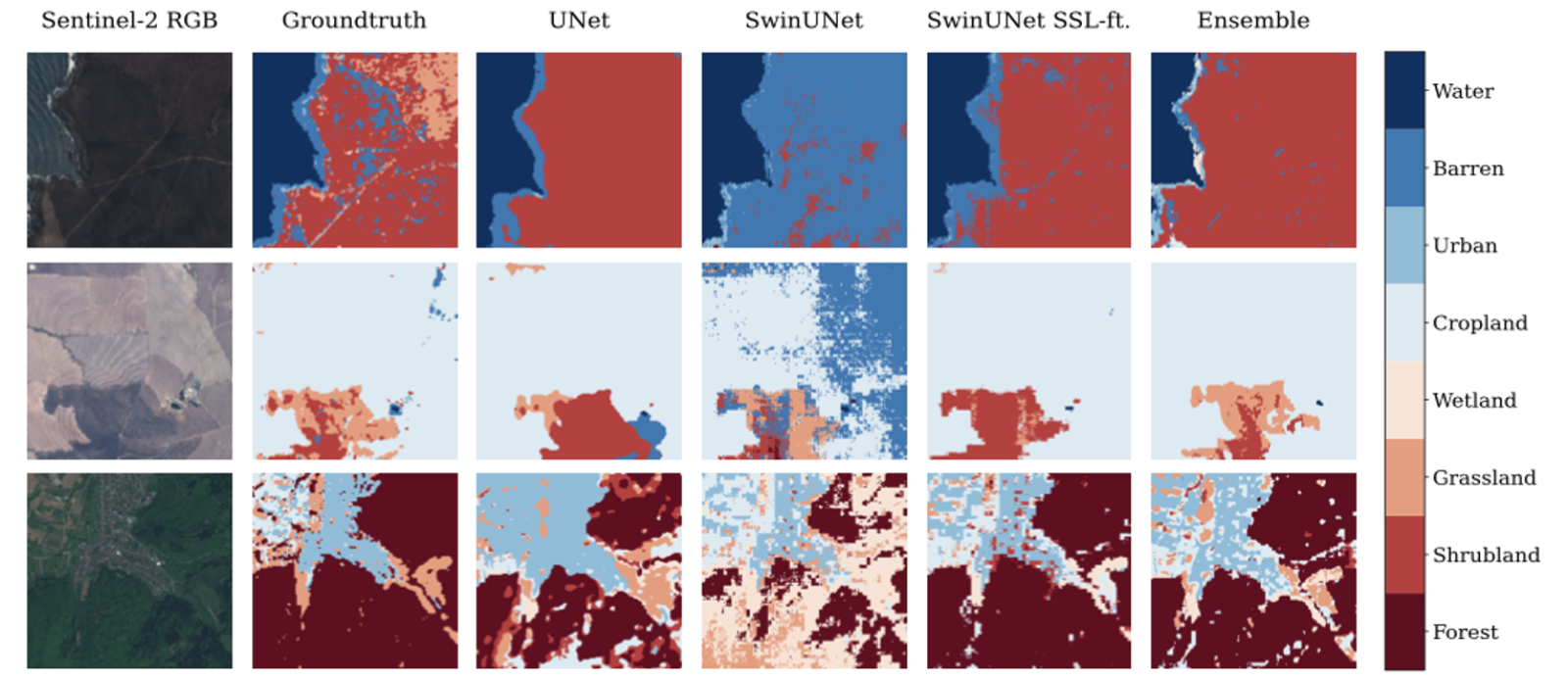
The results of this work include a set pretrained backbone architectures and have been published at the Earthvision workshop at CVPR 2023 and has been awarded the best student paper award!
Future Work
We would like to note that this line of research is now being funded by the Swiss National Science Foundation (SNF). The goal of this project is to combine self-supervised learning for different types of multi-modal Earth observation data. Stay tuned for our upcoming results!
Resources
-
Scheibenreif, L., Hanna, J., Mommert, M., Borth, D., “Self-Supervised Vision Transformers for Land-cover Segmentation and Classification”, Earthvision Workshop at IEEE/CVPR 2022, publication (open access). This work was awarded the best student paper award of the Earthvision 2022 workshop.
-
Scheibenreif, L., Mommert, M., Borth, D., “Contrastive Self-Supervised Data Fusion for Satellite Imagery”, International Symposium for Photogrammetry and Remote Sensing, publication, 2022.